


Installing and setting-up Remix
Remix can be installed using npm, as is common for JavaScript frameworks. You can simply create a new project using npx create-remix. In doing so, the script asks the user for preferences, such as the use of TypeScript or a preferred server implementation (Express, Vercel, Netlify, etc.), and creates a minimal project framework. Remix also offers more complex templates where pre-built stacks are preconfigured with database solution, integration and unit tests, deploy pipeline, and hosting provider. However, we want to focus less on these stacks and more on the core concepts of Remix.
Server-side rendering
Remix is meant for server-side rendered websites. But what does that actually mean? Rendering describes the process of an HTML document getting populated with content. A basic distinction is made between client-side and server-side rendering (Fig. 1).
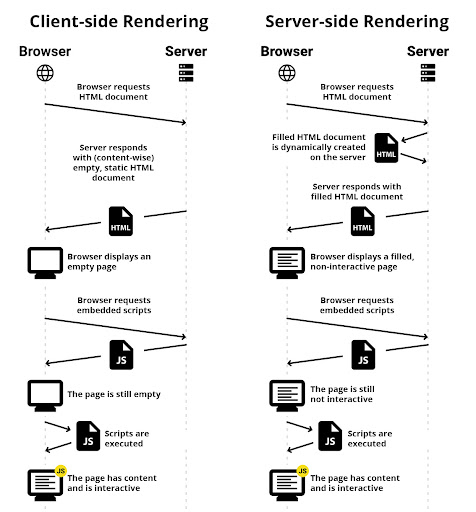
Fig. 1: Overview of client-side and server-side rendering with hydration
For example, if you create a React single-page application with create-react-app and deploy it to a web host, an HTML document is downloaded when you visit the website. However, the content of this document is limited to references on styles and scripts needed to build the website. Constructing the HTML structures only occurs in the browser, which is why we call it a client-side rendered website (CSR). It’s important to know that usually, all CSR routes sites are defined by the same HTML file, which also means that for a crawler the same metadata is visible for all routes. This is bad in web stores, since different embeddings are not created for different product routes.
If the web server fills the HTML document with content before transmission, this is called server-side rendering (SSR). Since the documents are created dynamically, the aforementioned problem with metadata is eliminated. However, the website takes longer to respond because the server must first assemble the response and cannot simply copy it from memory as it would with a static host.
Between CSR and SSR, you can still find Static Site Generation (SSG). Here, all site routes are pre-rendered and the HTML documents of all routes are uploaded to the web host. This approach can be interesting if the site contains few static routes, such as a portfolio or documentation site. For a web shop with hundreds of products that can be edited on the fly, this approach isn’t suitable.
Solutions from Remix
Remix creates the server that serves the React application as a framework. When a route is invoked, the Remix server renders the HTML document before it is transmitted to the user. The browser can render the site immediately. JavaScript is executed in the background, effectively making the site a client-side single-page application. The step where the client does the rendering is called hydration. As a result, Remix provides the benefits of SSR, such as dynamic metadata and faster rendering of content in the browser, as well as the benefits of CSR, such as making changes to the site without reloading an HTML document.
One problem with server-side pre-rendered web pages with client-side hydration is often that the page has already been rendered for the user before hydration, but is not interactive yet (Fig. 1, right column). Remix solves this problem by building the data concept on HTML forms. More on that in the section “Data Flow and Hydration”.
iJS Newsletter
Join the JavaScript community and keep up with the latest news!
Routing in Remix
Remix uses the directory to define routes. All JavaScript module files stored under app/pages are interpreted by Remix as route components. The name of the file defines the route segments. For example, a module under app/pages/products.tsx defines the /products route. Subfolders can be created for deeper routes. Variables can be defined in the file or folder name with a $ sign. For example, a file defined under app/pages/products/$productId.tsx will be included in all products/* routes.
The dropped files export a common React component via the default export. Features provided by React – such as hooks – can also be used here. In addition to the default export, you can provide other optional exports that can be used to query data, define troubleshooting, and declare metadata. But more about that later.
An interesting feature of Remix routing is nesting. Remix assumes that websites are usually hierarchical. For example, all routes on a website have the same navigation bar, account settings all have a sub-navigation, or all product pages have a consistent layout. Therefore, the modules stored under app/pages do not define the entire routes, but only route segments, as Figure 2 shows. Here, a product website is shown assembled from three segments (root component, $product-Id.tsx, and $variantId.tsx), and how the called URL is mapped to the route components.

Fig. 2: Visualization of nested routing.
The nesting is enabled by an <Outlet/> component provided by Remix. This can be included in the render function of a segment. When segments are assembled, the subsequent segments are included there (Fig. 3).

Fig. 3: Segments of a route are joined together
When rendering a route, Remix starts at the root under app/root.tsx and includes the next route segment in the <Outlet/> component. The next segment is then included in the included component. This continues until the whole URL has been mapped.
The question may arise, how does routing work with index pages? For example, if you want to list all categories on the /categories route, the obvious thought would be to put that listing in the app/routes/categories.tsx. However, the problem is that more specific routes, like /categories/123, would also render this listing. Remix solves this problem by using index segments. A module named index.tsx can be created in the app/routes/categories folder. Remix will prefer this index segment if it is the last element of the path (Fig. 4).

Fig. 4: Mapping of index routes and regular routes in the file system and in the URL.
Individual segments are rendered in parallel and in isolation from each other, and are assembled once all segments are complete. Isolation means that data cannot be shared between route segments, which may cause them to be requested multiple times. However, the advantage of this strategy is if errors occur in one segment, you can guarantee that the other segments will continue to work. Remix builds the error recovery strategy on this. You can export a catchBoundary and an errorBoundary in a route segment.
Functions are React components, just like the default export. If there is an error, the content of these React functions will be displayed instead of the actual content. Since the segments are independent of one another, the overlying segments remain interactive. If catchBoundary and errorBoundary are not defined, Remix will go up the segments to the root until a catchBoundary or an errorBoundary is found.

Data Flow in Remix
An important part of any web site is data. A web store, blog, or news site without data is … well, not exactly worth reading. Remix provides a data flow integrated with the routing. Each segment can provide a loader and an action function. These functions, unlike error and catchBoundary, are not JSX components, but return a Response. Loader and action can be compared to query and mutation, which are familiar from GraphQL.
Loaders are read operations, such as querying product information or blog entries. Actions, on the other hand, are write operations. They are used in log-ins, creating blog entries, or submitting comments, basically anywhere that modifies the state returned by the loader function.
The data flow can be represented by a triangle (Fig. 5). The corners represent the render, loader, and action functions. When a user calls the page, the loader first provides the required data. The data is passed to the render function. It can then define a form that calls an action. It modifies the state on the server, which also changes the state of the loader, leading to a change in the rendered content.

Fig. 5: Interactions between render, action, and loader functions.
It’s important to note that the loader and action function are not included in the client JS bundle. Each call to these functions happens on the Remix server. This also means that the function does not have access to browser APIs such as localStorage or sessionStorage. If you want to keep data between the browser and the server, a session cookie is recommended. Remix provides a cookie implementation that stores the data as a base64-encoded string. Listing 2 shows a session cookie in use.
The loader function must return a Response object. Response is a part of the Node.js API and describes an HTTP response. Response allows to return any content and set all headers. Through these headers, Remix also allows redirects or setting session cookies.
Remix provides some helper functions that abstract Response, such as the json function used in Listing 1 [1]. The data returned by the loader function can be used in the render function via the useLoaderData hook (Listing 1)
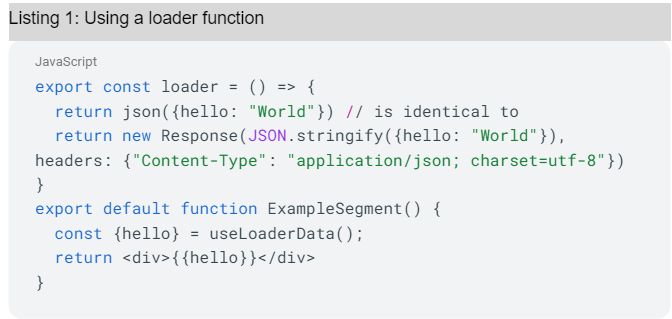
However, you usually want to pass data as well. For example, logging in without a way to pass the username and password is not really useful. The action function is used for this purpose. Actions are defined according to the same pattern as loader (Listing 2).
Accordingly, the actions can be called using HTML forms. Remix provides its own Form component, which is pre-rendered as a regular HTML form and replaced after hydration. So, the page remains usable even if it is not hydrated yet or JavaScript is disabled in the browser.
The values to be transferred are defined in <input> elements. If you want to define multiple actions per segment, Remix has the convention of “Intent”. Here, a hidden input field is used to define an action name, which is also transmitted when the form is submitted. On the server, the input field can be read and the correct logic executed. A log-in segment might look like the one shown in Listing 3. Two intents login and logout are defined in it. The relevant branch is then executed in the action. The beauty of this model is the separation between logic and rendering and the possibility of automatic revalidation.

After an action is invoked, Remix automatically triggers the loaders of all active segments in the hydrated state. If there are any changes to the site as a result of the action, Remix automatically makes them visible immediately.
Data Flow and Hydration in Remix
Behind the scenes, Remix creates an endpoint for each action and loader function through which the JSON data is accessed when the application is hydrated. This way, for new data, only the relevant data is transferred in JSON format, rather than the entire HTML document. If the application is not yet hydrated, the loader is called internally and the HTML document is returned with a modified state. For the action, Remix waits for POST requests containing the form data and responds with the modified HTML document.
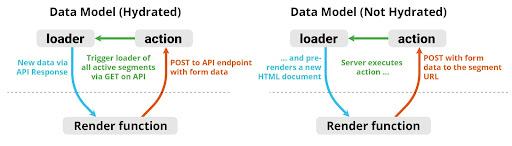
Fig. 6: Comparison of the processes of an action in a hydrated and non-hydrated application.
Progressive Enhancement
Through the data flow used, Remix allows developers to create websites so it works well without client-side JavaScript, but can also be enhanced through JavaScript. Besides data flow, this concept can be found in routing. After hydration, instead of a whole HTML document, only new data is requested as JSON and already preloaded before the page load thanks to the hover event.
This concept that JavaScript is not needed but improves the user experience is called Progressive Enhancement [2]. In my opinion, websites should use this concept wherever possible. Nothing is more confusing than a website that looks ready to load, but isn’t responsive to user interactions. Progressive Enhancement should also be considered especially because of trends towards increased mobile usage [3]. This is because websites take longer to load scripts, especially on smartphones, due to poorer wireless connections and weaker performance.
Remix and Next.js: A Comparison
In order to compare Remix and Next.js, you must first clarify which Next.js version or strategy is meant. As of version 13, Next.js offers a new routing system that resembles Remix’s routing system in many aspects. Before version 13, Next.js only offered “classic” routing. Next.js refers to this as the “Pages Router”. Pages could be placed in the pages folder, each defining the entire page. Next.js provides a similar system for routing pages. Instead of a loader, Next.js has getServerSideProps and getStaticProps. Both functions each define data that can be read and used in the render function via a function parameter.
There is no action like in Remix for Next.js page routing. You can define API routes that can be called in the render function with fetch, for example. Data flow is less integrated by the framework this way. Developers must take care of revalidation. This requires a separate API endpoint, because although Next.js automatically creates an API endpoint for getServerSideProps, the route URL is changed with a random seed in every build process.
Since version 13, there is new app routing. Instead of the pages folder, an app folder is used. Routing builds on nesting and, like Remix, it has benefits like parallelization, “data proximity”, less code duplication, etc. The new app routing also brings its own data concept with actions and revalidation, but it has a different syntax and approach.
Conclusion
Remix is a fresh React framework that specializes in server-side rendered websites. It tries to map the HTML5 API as closely as possible, building the data concept on top of the forms API. It’s a strategy so old that it feels new again. Despite the innovative concepts Remix brings to the table, it’s unlikely to prevail over Next.js as a framework for server-side rendered websites. Next.js is simply too widespread and established. There’s already a large and stable Next.js ecosystem of tooling, resources, libraries, and developers that Remix cannot compete with.
So, has Remix failed? No, quite the opposite! Even if it doesn’t catch on as the “go-to” framework, Remix illustrates the benefits of paradigms like nested routing and Progressive Enhancement. It has likely indirectly contributed to a better routing concept for Next.js and possibly other frameworks too.
Remix is constantly evolving and will surely bring more innovations. Currently, the Remix team is experimenting with a new routing declaration strategy that does away with subfolders altogether. Who knows, maybe this strategy will be found in other frameworks in the near future?
Links & References
[1] Remix.run – documentation page for the json helper function: https://remix.run/docs/en/1.16.1/utils/json
[2] MDN definition of “progressive enhancement”: https://developer.mozilla.org/en-US/docs/Glossary/Progressive_Enhancement
[3] Desktop and mobile usage market shares from 2011 to 2022: https://gs.statcounter.com/platform-market-share/desktop-mobile/europe#yearly-2011-2022
[4] Twitter status of Lee Robinson: https://twitter.com/leeerob/status/1465702417513680897





