
How did we get here?
Since the invention of the web in 1991, we’ve seen steady progress in the capabilities of the fundamental building blocks of the web: HTTP, HTML, and URLs.
- HTTP/0.9: 1991, RFC
- GET only, HTML only
- HTTP/1.0: 1996, RFC1945
- POST and other verbs, MIME
- HTTP/1.1: 1997, RFC2068,2616
- Keepalive, pipelining, host header, updated in 2014
- HTTP/2: 2015, RFC7540
- SPDY, binary protocol, multiplexed streams
- HTTP/3: 2022, RFC9114
What did HTTP/2 change?
Binary protocol
Switching to a binary protocol represented a major shift in HTTP’s architecture, and made several other options possible. This enhanced protocol was initially available in the form of “SPDY”, and was implemented in several browsers and servers as an experimental extension that eventually evolved into HTTP/2.
Header compression
Text-based protocols are not good for operations like compression and encryption, and the binary protocol allowed HTTP to enable compression of HTTP headers, not just the body.
Multiplexing
HTTP initially tried to improve the performance of parallel response delivery by using multiple TCP connections (defaulting to six per domain in most browsers), but this also increased memory consumption and latency as each connection had to do a complete TCP and TLS handshake – this overhead is clearly visible in browser development tools. Multiplexing allowed multiple resources to be transferred over the same TCP connection at the same time. This was a step up from the pipelining and keepalive introduced in HTTP/1.1 as it allowed dynamic rescheduling of resource delivery, allowing for example an important, but small, JSON response to sneak past a bigger, but less important image download, even if it was requested later.
HTTP initially attempted to improve performance for parallel response delivery by allowing multiple TCP connections (typically defaulting to six per domain in most browsers). However, this approach also increased memory consumption and latency due to each connection requiring a full TCP and TLS handshake. This overhead is readily apparent in browser developer tools. Multiplexing, introduced in HTTP/2, addressed this by enabling the transfer of multiple resources over a single TCP connection concurrently. This marked a significant improvement over the pipelining and keepalive mechanisms of HTTP/1.1. Multiplexing allows for dynamic rescheduling of resource delivery, enabling a critical but smaller JSON response to bypass a larger, less important image download, even if it was requested later.
Server push
Server push eliminated some round trips, for example, allowing multiple image or JavaScript sub-resources to be speculatively bundled in the response to a single request for an initial HTML document. Despite the promise of this, especially for mobile applications, this approach has not seen much use.
TLS-only
Despite a great deal of push-back from corporate interests, and that HTTP/2 was ultimately technically allowed to be delivered over unencrypted HTTP, browser makers rejected the entire premise, and all popular implementations only support HTTP/2 over HTTPS, raising the security floor for everyone.

What problems does HTTP/2 have?
Head-of-line blocking
In early HTTP, every resource transfer required setting up a new TCP connection. HTTP 1.1 added pipelining and keepalive, allowing multiple requests and responses to use the same connection, removing a chunk of overhead. This was extended in HTTP/2 multiplexing, allowing dynamic reordering and reprioritisation of those resources within the connection, but both mechanisms are subject to the same problem. If the transfer at the front of the queue is held up, all of the responses queued up on that connection will stall, a phenomenon known as head-of-line blocking.
Network switching
An individual HTTP client connection is usually identified by the combination of its IP and port number. When a client transitions between network connections, for example moving from WiFi to mobile when leaving your house, both of these will change. This necessitates a completely new TCP connection with the new values, incurring overhead in setting up a new TCP and TLS connection from scratch. In situations when connections change rapidly, for example on a high speed train where connections are handed off between cell towers, or in high-density networks, for example, in a stadium, this can result in clients continuously reconnecting, with a dramatic impact on performance.
It’s stuck with TCP
HTTP/2 is built on TCP, and as such inherits all of its shortcomings. TCP was designed 50 years ago, and while it’s done remarkably well, it has some problems for the modern Internet that its creators did not foresee. However, we are stuck with it as it’s implementation is typically tied to the client and server operating systems that use it, so we can’t change it to suit one specific networking application, in this case HTTP.
TCP congestion control
One of the key things that can’t be changed easily in TCP is the congestion control algorithms that kick in when on busy networks. A great deal of research over the last 50 years has produced approaches to handling busy networks that are superior to what’s in TCP, and our inability to deploy them represents an ironic bottleneck of their own.
What are QUIC and HTTP/3?
QUIC (originally a backronym of “Quick UDP Internet Connections”, but that’s never used in practice) was started at Google in 2012. SPDY, that became HTTP/2, was a stepping stone to improvements in the low-level protocols that we rely on to deliver the web. Fundamentally, QUIC is a reimagining of TCP. Because we can’t replace TCP in every device in the world, it needed to be built on an existing lower-level protocol that provides a functional foundation, and a great fit for that is UDP, the user datagram protocol. UDP is much simpler than TCP, and lacks all kinds of features such as reliable delivery, connection identification, lost packet retransmission, packet reordering, and so on. The advantage of UDP is that it’s very fast and has very little overhead. UDP is most commonly used for protocols that don’t mind losing a bit of data here and there – you really don’t care that much about a few pixels glitching in the middle of a video call’s frame, or a little click in an audio call; it’s more important that the stream keeps going. It’s also used for DNS, in scenarios where you don’t care which DNS server responds, so long as one of them does.
At this point you’re probably thinking, “but we need reliable delivery for the web!”. That’s true, and it’s why we’ve used TCP to date. It provides the reliability guarantees we need, along with a bunch of other features we might not even use. But we can build reliable transports on top of unreliable ones – after all, this is exactly what TCP does on top of IP. So QUIC reimplements much of what TCP does, but on top of a UDP base and without all of TCP’s historical baggage, QUIC gives us free rein to rewrite things to better match how we want the web to work.
At the same time, Google was also looking at how encryption (specifically TLS) is used by HTTP. It’s all very ISO-network-diagram-friendly to use TLS as an independent layer, but if we look at the impact of this approach it becomes clear that TLS adds overhead in the form of latency on every request. So Google sought to integrate TLS (specifically TLS 1.3) directly into QUIC. Ultimately this allows what were previously three separate layers for TCP, TLS, and HTTP to be combined into a single layer with much lower overhead.
iJS Newsletter
Join the JavaScript community and keep up with the latest news!
As terms, QUIC and HTTP/3 are often used interchangeably, and though QUIC can exist by itself, HTTP/3 can’t exist without QUIC. While QUIC can be used as a transport for other protocols (covered below), at this point it’s rare enough that it can be assumed that if you say QUIC, you also mean HTTP/3.
QUIC is a new protocol that’s not part of the OS’s standard networking stack, so it had to be implemented in “userland”, directly inside the applications that use it – browsers, HTTP clients, servers, etc. This does mean that there are multiple independent implementations, which is a recipe for more bugs and interoperability issues, but at the same time it also means that those bugs are easier to fix – application updates can be developed and rolled out much faster than those for an operating system.
If you’ve ever used mosh (mobile shell) as a remote admin tool instead of SSH, and appreciated the joys of reliable terminal sessions that never die, you’ve already experienced the advantages that a connectionless protocol built on UDP can bring, as that’s exactly what mosh does.
QUIC was eventually formalised into RFC9000, and HTTP/3 over QUIC in RFC9114.
Perhaps QUIC’s biggest secret is that you’re using it already. QUIC was implemented in most browsers in 2022, and CloudFlare reported that HTTP/3 use overtook HTTP/1.1 in that same year.
Head-of-line blocking (HOLB)
I mentioned HOLB earlier. This occurs in HTTP/2 because while we implemented multiplexing within a single TCP channel, and we can reorder and reprioritise the transfers that are occurring within it, it’s still subject to TCP’s own limitations because TCP knows nothing about HTTP. QUIC allows us to do away with that. UDP’s connectionless approach lets every transfer proceed independently; holding up one transfer has no effect on the others.
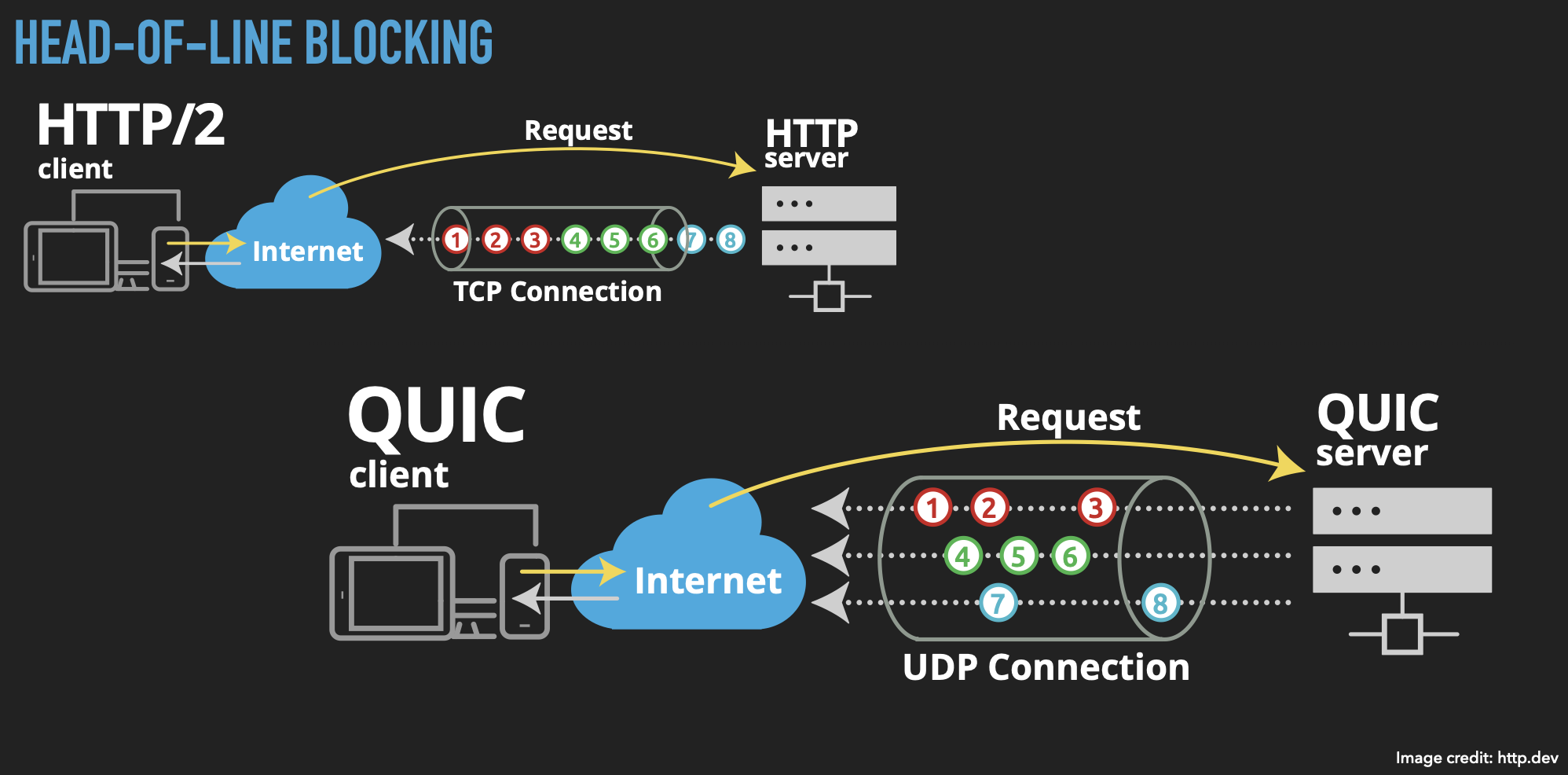 fig1: Head-of-line blocking
fig1: Head-of-line blocking
Network layers
The ISO 7-layer model has had much criticism because there are so many exceptions to its academic, isolated approach; HTTP/3 blurs the boundaries even more, for considerable gain.
In HTTP/1.1 we had 2 or 3 layers depending on whether we added TLS into the mix. HTTP/2 clarified that by enforcing a TLS layer. HTTP/3 mixes it all up again by dropping TCP in favour of UDP and combining the TLS and HTTP layers.
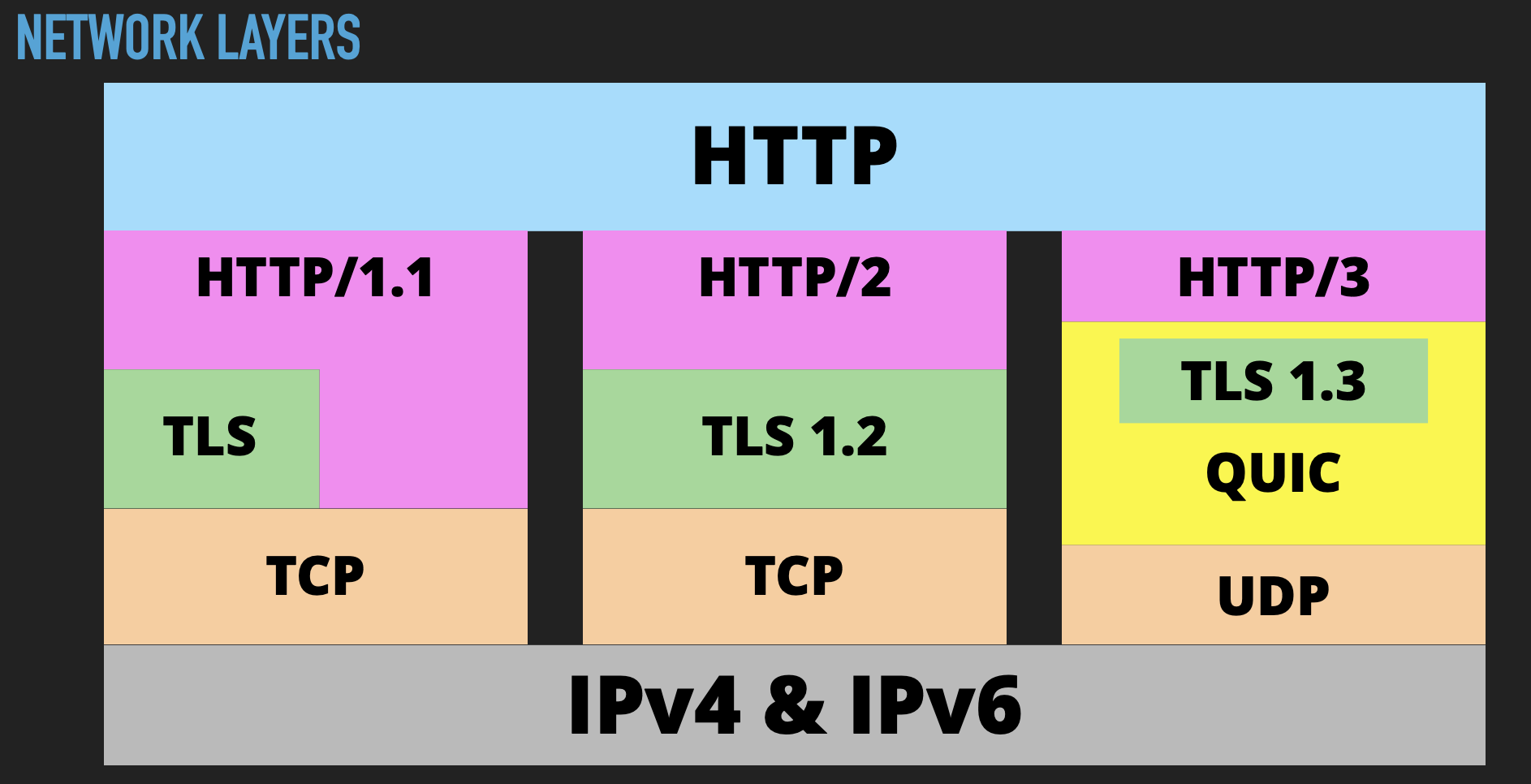 fig2: Network Layers
fig2: Network Layers
All-round improvements
Let’s look at the overhead in creating a new connection across the three most common stacks. HTTP/2 with TLS 1.2, HTTP2 with TLS 1.3, and HTTP/3 on QUIC.
With TLS 1.2, the first request will require no less than 4 network round trips between client and server before the first HTTP response is delivered. One for TCP’s SYN/ACK handshake, two for TLS key exchange and session start, and finally the HTTP request itself. TLS 1.3 improved on this by combining its two round trips into one, saving 25%. HTTP/3 saves an additional trip by combining the equivalent of the TLS handshake (which no longer exists in QUIC) with the TLS setup, followed by the HTTP request, giving a 50% improvement over HTTP/2 with TLS 1.2.
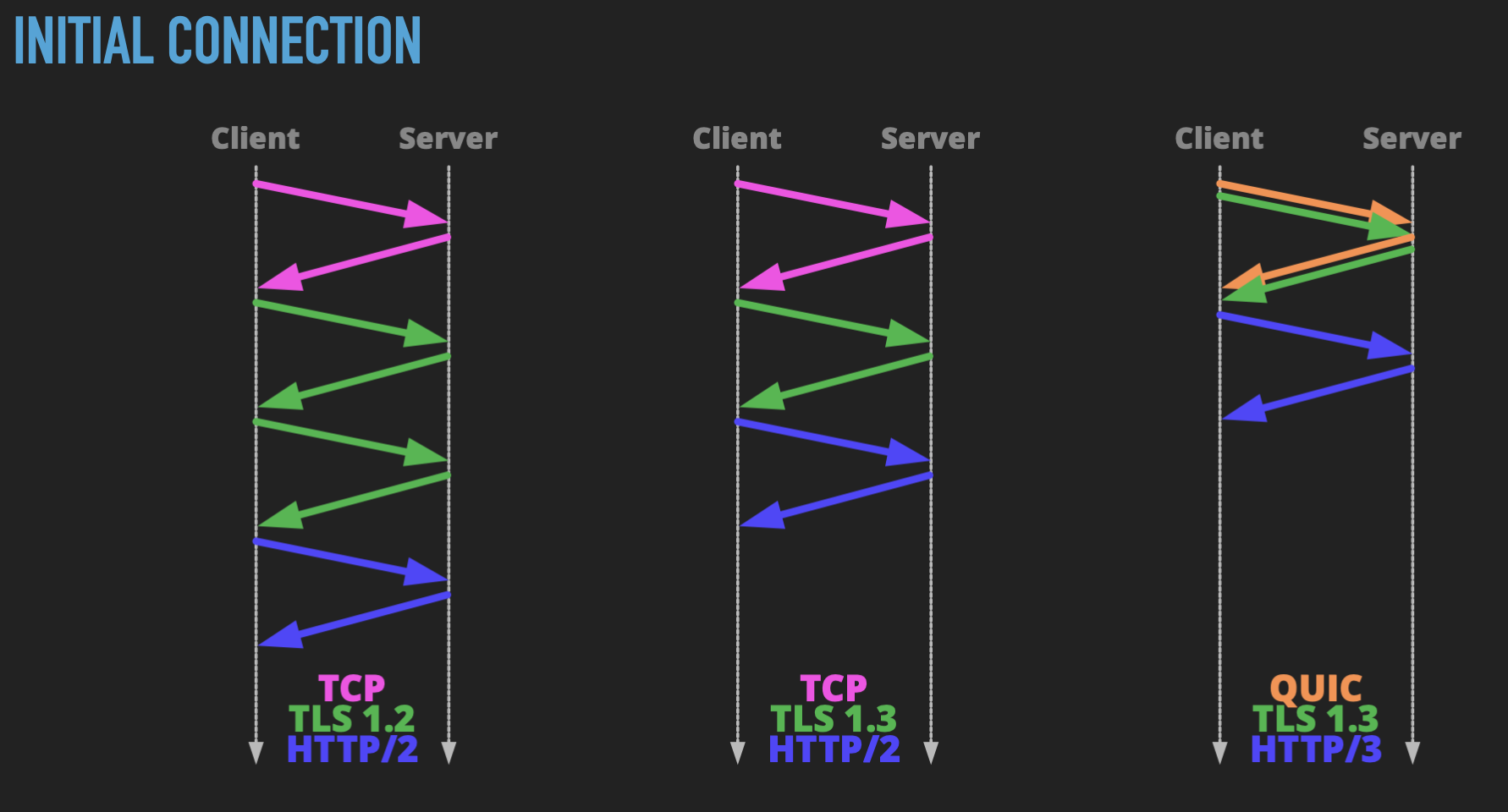 fig3: Initial connections
fig3: Initial connections
When a client makes subsequent requests to the same server, we can save some effort – we already know what TLS configuration to use, so no key exchange or cipher negotiation is needed. This allows a resumed connection with HTTP/2 over TLS 1.3 to take only 2 network round trips. HTTP/3 goes further though, as it can combine all three into a single round-trip, halving the latency. When TLS 1.3 was announced back in 2016, this was touted as “0-RTT”, which was definitely an improvement, but it ignored that it still had TCP’s overhead. HTTP/3 delivers it for real.
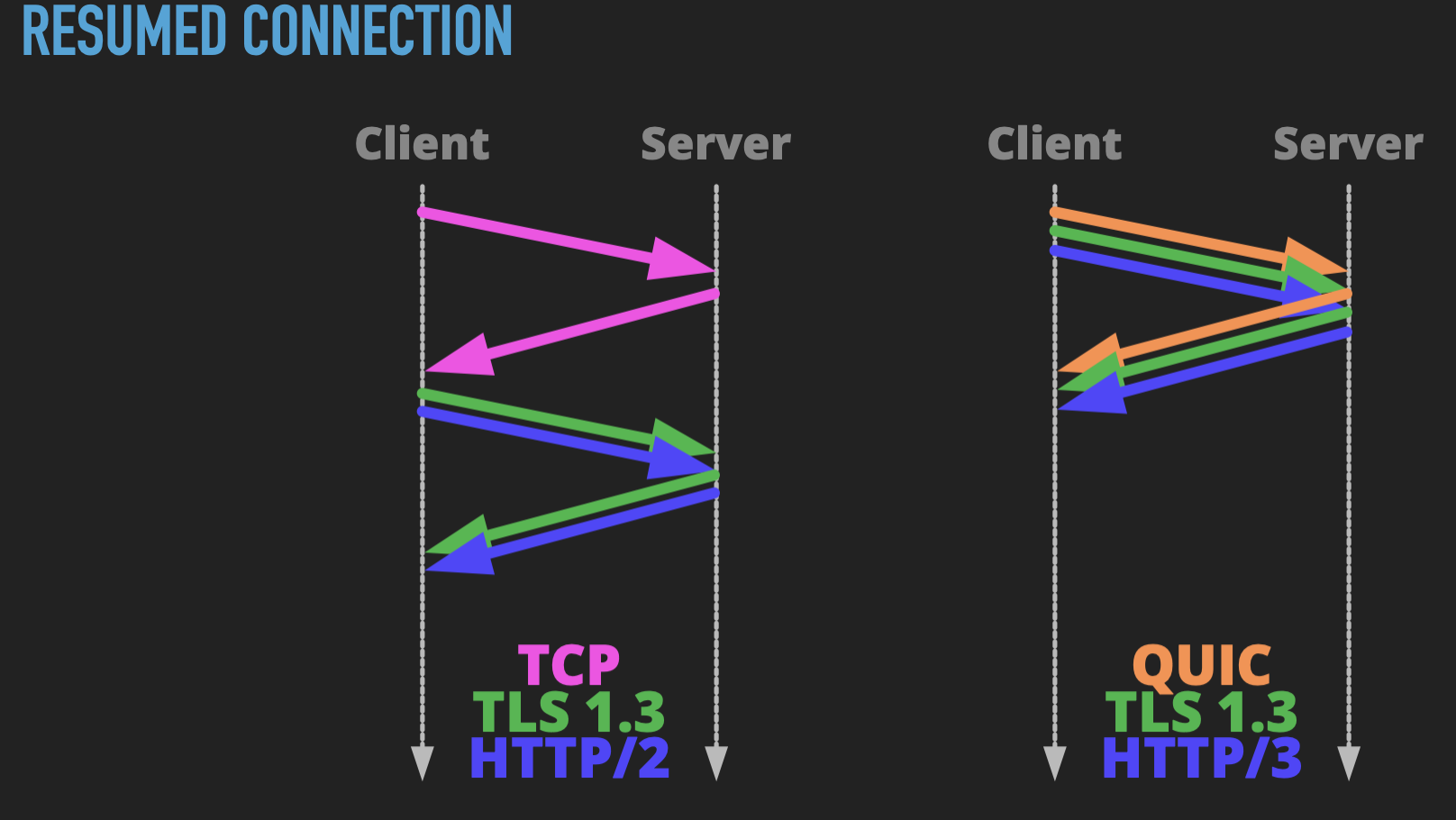 fig4: Resumed connections
fig4: Resumed connections
Network switching
I mentioned earlier that TCP connections are identified by the combination of the client’s IP + port number, resulting in needing to re-establish connections when these change. QUIC avoids this by not identifying connections this way and instead assigns a connection identifier (a random number) during the initial connection. All subsequent requests can use that identifier regardless of which network they are using. A major advantage of this is it means that resumed requests are much more likely to happen, as the connection does not need to be reset every time we switch networks, which is great news for busy or slow networks.
That sounds cool, but also like a bit of a privacy problem, as it means that you can be traced as you move between networks. Fortunately, this is something QUIC’s designers thought about. Instead of assigning you a single, static identifier on the initial connection, you’re assigned a pool of random values, and each time you switch networks the next value is used, so the server and client know you are the same user, but the networks in between do not. Clever, huh?
Header compression
When HTTP/2 introduced its binary protocol, it was able to add compression of HTTP headers, which were uncompressed in previous HTTP incarnations. In these days of chunky JWTs and Content-Security-Policy HTTP headers, this can represent a fair saving in the data required to transfer them.
Unfortunately, HTTP/2’s HPACK compression is dependent on reliable delivery of the underlying data, so everything has to be received in the compressed chunk’s entirely before it can be decompressed – it’s really another form of HOLB. HTTP/3 switches to a compression scheme called QPACK which is slightly less efficient, but avoids this congestion problem.
Security upgrade
While TLS 1.3 has been available as an option for a long time – My first conference talk on TLS 1.3 was in 2016 – QUIC makes it a requirement. Because QUIC is completely integrated with TLS, more of the data is encrypted – the only things not encrypted are the connection IDs, which are just random numbers anyway.
TLS 1.3 brings a bunch of security improvements over 1.2:
- Lower overhead, as we’ve seen
- No weak cipher suites, key-exchange algorithms, MACs, or hash functions
- Perfect forward secrecy in all cipher suites
- Downgrade detection
HTTP/3 is even safer than HTTP/2 + TLS 1.3 because more of the connection is encrypted – encryption kicks in earlier in the process when using QUIC, and encrypts its headers, whereas even TLS 1.3 does not.
All that said, HTTP/3 shares the same problem with resumed connections that HTTP/2 does in that it is not especially well defended against replay attacks. For this reason resumed connections should only be used for idempotent requests that do not change server state, which typically means GET requests only.
HTTP/3 implementations
HTTP/3 is harder to implement than HTTP/2 because every application has to implement all of the underlying QUIC protocol as well at both ends of the connection. Fortunately this speed bump is now largely in the past as HTTP/3 has been implemented in the majority of places that it’s needed.
Unsurprisingly, the first HTTP/3 client was Chrome, then in Chromium based-browsers that inherited from it, such as Microsoft Edge, soon followed by Firefox and Safari, including in iOS 15.
Servers were quick to follow, with Litespeed taking the chequered flag, followed by Caddy, Nginx, IIS (in Windows Server 2022), and HAProxy. The one straggler yet to make the finish line is Apache, but I’m sure it will get there soon. Libraries are vitally important for many implementations, saving a lot of development effort, and h2o, nghttp3, libcurl, and OpenSSL now all have HTTP/3 support.
Several cloud services, most notably CloudFlare, have updated their front-ends to support HTTP/3, so if you’re using that, it’s likely you have HTTP/3 support without even noticing!
Remember that all of these are “userland” implementations, and so are not subject to OS stagnation; so long as the OS supports UDP (and they all do), we’re good to go.
Deploying HTTP/3
We do have a slight chicken & egg problem: How does a client know that it can use HTTP/3? If the client just tries to use it, the server might not support it, and so we will be stuck there waiting for it to time out before we can fall back to HTTP/2 or further. This isn’t really acceptable, so we need to approach it from the other direction, providing hints to the client that they can upgrade their connection to HTTP/3 after they have connected by HTTP/2. This works much as we handle unencrypted HTTP – clients connect to the unsecured endpoint, and are then redirected to the secure one.
There are two key mechanisms available to do this. The Alt-Svc HTTP header, and the SVCB DNS record type.
The Alt-Svc HTTP header is defined in RFC7838, and is short for “Alternative service”, and works in a similar way to Strict-Transport-Security (HSTS) for HTTPS. A typical header might look like this:
Alt-Svc: h3=":443"; ma=3600, h2=":443"; ma=3600
This tells the client that the service that it’s connecting to is available on HTTP/3 on UDP port 443 and HTTP/2 over TCP on port 443, in that order or preference. In both cases the client is also told that these services will be available for at least the next 3600 seconds (1 hour). Once the browser has seen this header, it can then set about switching to the faster protocol.
The SVCB (“Service Binding”) DNS record type is defined in RFC9460, and looks like this:
example.com 3600 IN HTTPS 1 . alpn="h3,h2"
This says to a client that the _example.comdomain offers HTTPS service over HTTP/2 and HTTP/3 for at least the next hour. There is a bit of a silly issue here - we could have found out the same thing from anAlt-Svc` record just by going straight to the service. So we have just swapped an HTTP request for a DNS lookup, both of which are likely to have about the same network overhead. However, we need to do a DNS lookup anyway to discover the IP address to connect to, so this seems like extra work. Fortunately, the SVCB records authors thought of this too, and the response can include IP address hints, like this:
example.com 3600 IN HTTPS 1 . alpn="h3,h2" ipv4hint="192.0.2.1" ipv6hint="2001:db8::1"
This gives us both the information about the service availability and the IP addresses that we need to connect to; two birds, one stone.
SVCB has another trick up its sleeve: you can provide multiple records with different priorities and abilities:
example.com 3600 IN HTTPS 1 example.net alpn="h3,h2"
example.com 3600 IN HTTPS 2 example.org alpn="h2"
This says that the service is available on example.com over HTTP/2 and HTTP/3, but is also available as a fallback (with a higher weighting value meaning a lower priority) over HTTP/2 only at example.net.
Nginx config example
I have to say that Caddy is the easiest to configure for HTTP/3 because it’s enabled by default. That’s possible because of its integrated automatic certificate setup feature and you don’t have to do anything in addition. However nginx is extremely popular, so here’s how to make it work there.
server {
listen 443 ssl;
listen [::]:443 ssl;
listen 443 quic;
listen [::]:443 quic;
http2 on;
add_header Alt-Svc 'h3=":443"; ma=86400';
server_name example.com www.example.com;
The first two lines will be familiar territory for nginx users – it’s not changed at all, though nginx moved the http2 switch from the listen directive to its own directive in version 1.25.1 in 2023.
We then add two lines to add listeners for QUIC on IPv4 and 6, on the same interfaces and port number as for HTTP/2, but there is no clash because they are on UDP instead of TCP.
You can find the nginx QUIC docs at nginx.org/en/docs/quic.html.
We then add an Alt-Svc header indicating that we recommend moving to HTTP/3 and it will be available for at least the next day. We don’t actually need to specify that we also offer HTTP/2, because it’s implicit – if we didn’t the client wouldn’t get to see this at all.
After this we carry on with all the other nginx config directives we might need – the server name, root directory, certificate locations, additional headers, logging config, etc. Remember that HTTP/3 requires TLSv1.3.
You also need to allow inbound traffic to UDP port 443 in your firewall and possibly in your cloud provider’s security groups too. In ufw on Debian and derivatives, you’d add it like this:
ufw allow proto udp from any to any port 443
In the next major releases of the Debian and Ubuntu packages later in 2024, you’ll also find support for an nginx ufw application (thanks to a PR by yours truly) that allows you to write this in a slightly prettier way, supporting all of HTTP/1, 2, and 3 in one line:
ufw allow from any to any app "Nginx QUIC"
Optimising for HTTP/3
Despite all the underlying changes, HTTP/3 remains unchanged with respect to HTTP semantics, so when it comes to optimisation it’s also the same as for HTTP/2. The short version:
- Use few domains for loading content (reducing the number of DNS lookups and connection setups)
- Don’t worry about bundling; request count doesn’t really matter any more, and larger numbers of small requests are easier for the browser to cache and manage. Think of webpack as an antipattern!
- Make use of defer / preload / async directives for lazy-loading resources, letting the browser schedule them most efficiently.
iJS Newsletter
Join the JavaScript community and keep up with the latest news!
Testing HTTP/3
Testing HTTP/3 is slightly tricky. Until it sees the Alt-Svc header, a client doesn’t know it can use HTTP/3, so the very first request will be HTTP/2 (unless it’s done an SVCB lookup).
That status will persist for the max-age of the Alt-Svc header, so you want to keep that very short while testing. One trick I learned when playing with this is that browsers forget the max-age value if you use incognito/private browsing windows, so use that if you want to be able to see the 2 to 3 handoff repeatedly.
The first request will always be over HTTP/2, but you can’t predict exactly when the browser will switch to HTTP/3 for sub-requests. Browsers optimise very aggressively, so after it’s seen the Alt-Svc header, the browser may issue sub-resource requests simultaneously over both HTTP/2 and HTTP/3 for the same resource as a way of measuring which provides the best performance, and then use that result for subsequent requests.
If you open the network tab in Chrome’s developer tools, right-click on the request table’s header and enable “Protocol”, you’ll see a table column that shows what protocol the browser is using for each request. You should expect to see h2 for the first request, the further h2 requests for sub-resources, but at some point you’ll see it switch to h3. You might expect a reload to result in h3 or everything, however, you may find that Chrome classes anything delivered from its local cache as h2, even though it has never actually hit the network. Disabling the cache should allow you to see that everything has switched to h3 on reload. If you roll your mouse over the value in the protocol column, it will tell you why it selected that protocol, which is very useful for diagnosing connections that don’t seem to make the switch (e.g. if your browser finds that your site’s HTTP/3 responses are slower than HTTP/2, it won’t use them).
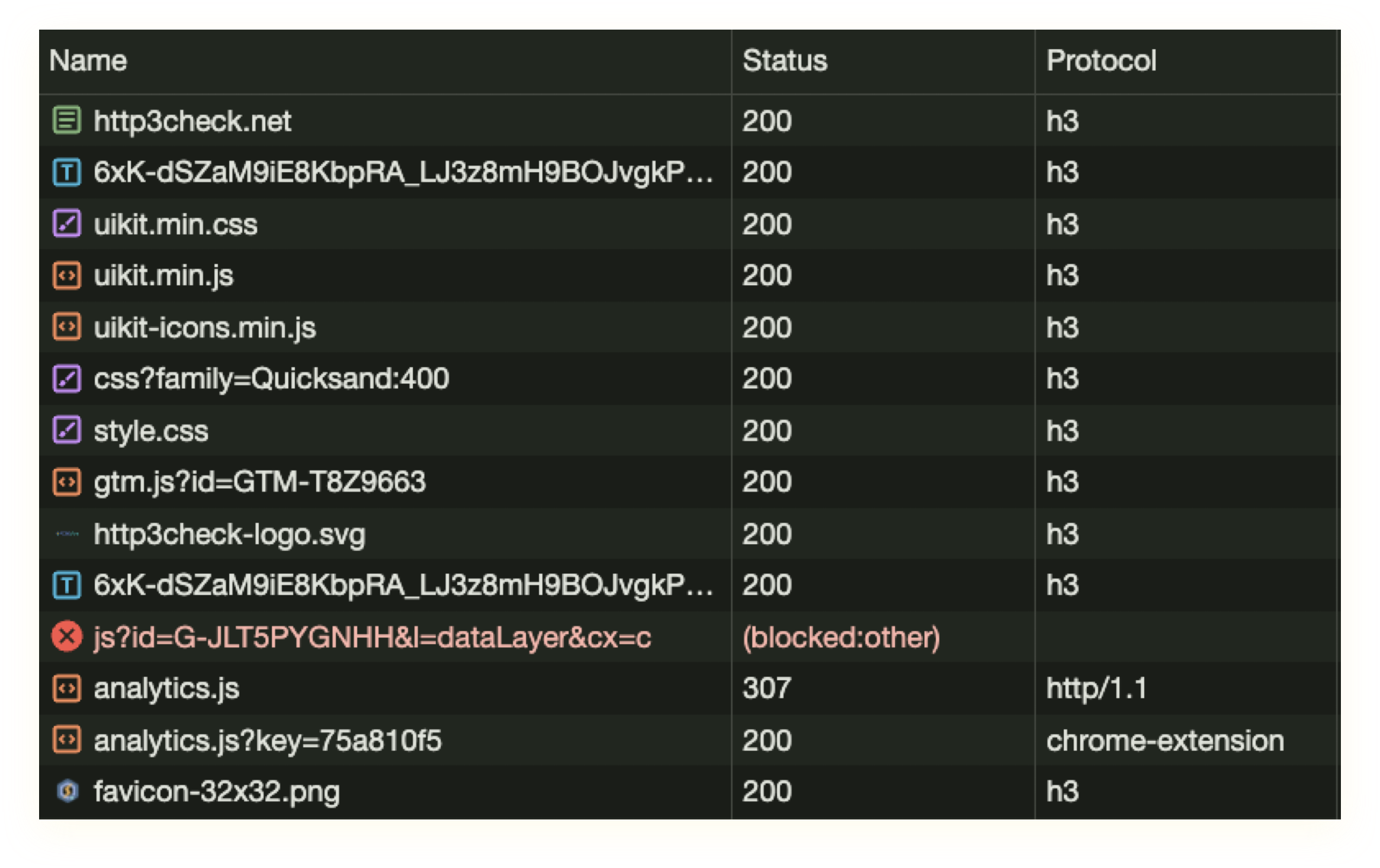 fig5: Dev tools view showing protocol column
fig5: Dev tools view showing protocol column
There is a handy testing service at http3check.net that will confirm that your site is delivered over HTTP/3. There is a Chrome extension called HTTP Indicator that displays a little lightning bolt icon in your toolbar – blue for HTTP/2, orange for HTTP/3.
Crunch time: Is it actually faster?
Unfortunately, the answer here is “it depends“. As you’ve seen, it can be difficult to measure, but the biggest payoff will be in situations there HTTP/3’s features make a difference, which will be when you have any combination of:
- Low bandwidth
- High congestion
- High latency
- Frequent network switching
So if you’re testing this on your company’s fast fibre connection or good domestic broadband, you won’t see (or measure) any practical difference. But if you’re up a mountain in a country the other side of the world, with a weak signal, switching between roaming services during a major sporting event, it’s much more likely to help.
In 2022, Google reported a 14% speed improvement for the slowest 10% of users. Fastly/Wix reported an 18-33% improvement in time to first byte for HTTP/3.
This is really HTTP/3’s payoff – it raises the performance floor for everyone; those with the worst connections are the ones that will benefit most.
HTTP/3 problems
Not everything is rosy in the HTTP/3 garden; there are new opportunities for things to go astray. Networks might block UDP. There is latency in version discovery. It’s new, so will have more bugs. That more is encrypted is a double-edged sword; the increased protection makes it more difficult to do do low-level network analysis and troubleshooting, and making it much less friendly to corporate monitoring.
The future of QUIC
QUIC used a deliberately dynamic specification. Soon after the original 1.0 release. version 2 was released in RFC9369. This was essentially unchanged, but it forced implementors to cope with version number changes to prevent stagnation and “ossifcation” like MIME 1.0 experienced. This is especially prevalent in “middleboxes” that provide things like WAF and mail filtering.
QUIC features pluggable congestion control algorithms, so we are likely to see QUIC implementations tuned for mobile, satellite, low-power, or very long distance networks that have different usage and traffic profiles to broadband.
Though QUIC and HTTP/3 are very closely tied, it’s possible for other protocols to take advantage of QUIC’s approach, and there have already been implementations of SSH over QUIC and a proposed standard for DNS over QUIC.
What are you waiting for?
Go configure HTTP/3 on your servers now!
Further reading
- https://www.debugbear.com/blog/http3-quic-protocol-guide
- https://http.dev/3
- https://www.csoonline.com/article/569541/6-ways-http-3-benefits-security-and-7-serious-concerns.html
- Robin Marx at SmashingConf: https://vimeo.com/725331731




