When considering how to store information for a website or web application, you might initially consider creating a web storage API to store data in a relational database such as MariaDB or a document database like MongoDB on a server. Yet, the browser offers numerous storage options that can be leveraged for various needs.
Understanding the different storage facilities inside modern browsers is crucial for web developers. By looking at their pros and cons, you can make smart choices for your next project. This will help you create efficient and effective web applications.
1. Cookies
Website cookies, or HTTP cookies, are tiny text files stored in a user’s web browser when they visit a web page. These cookies can contain information that helps the website remember the user data or their preferences and improve the browsing experience.
Cookies are commonly used for authentication and session management. When a user logs into a website, a cookie with their login information is created on the server and stored in the web browser. This allows the website to recognise the users and keep them logged in as different page loads.
In addition, cookies are often used for personalisation purposes. They can store user preferences, such as language settings or display preferences so that the website can provide a customised user experience.
Setting cookies
Setting cookies with JavaScript Code is somewhat cumbersome because it’s written as a string containing all the cookie’s attributes.
Example 1.1

In example 1.1, a cookie is created and saved with the name Sandwich and the value Turkey separated by an equal sign. The string also contains the cookie’s path and expiration date.
By default, the path is the current path, the page’s location that creates the cookie. If that path is a website subfolder, like test.com/cookies, the cookie will only be available for pages that are descendants of that path. If you want the cookie to be available on the whole website, make sure you include the root path, as in the example.
The max-age attribute defines a cookie’s end date. You can provide a date using the expires attribute in GMT format, but giving a max-age in seconds is easier. In example 1.1, the cookie will be deleted after one year of storage. Omitting this attribute will turn this cookie into a session cookie, which means it will be deleted after closing the browser.
Cookies are accessible through the browser DevTools. In Safari and Firefox browsers, they are available on the Storage tab, and in Chrome and Edge, they are present on the browser tab. Be aware that users can also access the cookies this way and alter them at will. The same goes for all the storage options mentioned further in this article.
Deleting cookies
If needed, the cookie can be removed by setting the max-age to 0, as shown in example 1.2. It is matched on the name and path; the cookie’s value is irrelevant in this case.
Example 1.2

A shopping website can also use cookies to remember the user’s shopping cart items. A benefit of using a cookie is that it is automatically sent to the web servers on each request, giving it direct access to the data. I prefer to store the contents of a shopping cart in a database on the server side and only save a unique reference for that cart in either a cookie or local storage.
Cookie Store
Setting a cookie, as in example 1.1, is a synchronous action. This means that any subsequent JavaScript execution has to wait until it is finished. Interacting with a cookie is also impossible from within a Service Worker.
To solve both these problems and to overcome the tedious process of setting a cookie with a string, the Cookie Store is available in Chromium-based browsers, such as Chrome, Edge, and most common Android browsers.
Service Worker
A Service Worker is a JavaScript file that mediates between the browser and the server. It can intercept and alter each request and reply to it from the server. It runs in a separate thread so that it won’t slow down any script related to the website. It also doesn’t have access to the website’s Document Object Model (DOM) or any cookies set in the browser, except when created with the Cookie Store.
Setting cookies
Setting cookies with the Cookie Store is more straightforward, as shown in example 1.3.
Example 1.3

This will create a session cookie named Favorite with the value Chocolate. Passing an object can set more options, like the expiration date (unfortunately, max-age is unavailable); see example 1.4.
Example 1.4

Deleting cookies
Deleting cookies is easy; a separate method only requires the cookie name (example 1.5).
Example 1.5


2. Web Storage
Web Storage is a mechanism for storing data as short—or long-term key-value pairs. Since the keys and values are always strings, objects and arrays must be converted, as shown in examples 2.1 and 2.2.
Example 2.1: converting objects

Example 2.2: converting arrays

Local Storage
The data stored in Local Storage is not bound to a session (tab or window) and will persist and be available on the next visit. However, data saved in a “private browsing” or “incognito” session will be deleted afterwards.
Web Storage provides straightforward methods to store, retrieve and delete data.
Example 2.3

A practical example is used on the website cfp.watch, where favourites are stored in Local Storage. Next time the user visits the website (with the same browser), these favourites will be available again.
Session Storage
Localstorage and sessionstorage works the same with one big exception: stored data will be cleared when tab or browser is closed.
The available methods are similar.
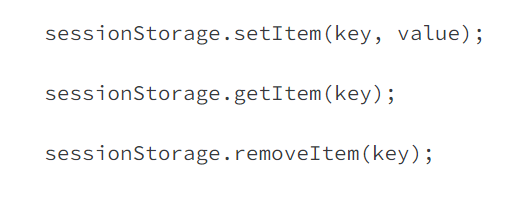
Session Storage can store temporary data or state for a web application when you’re not using a state management library or frameworks like Redux or Pinia.
3. WebSQL
WebSQL was an attempt to bring SQLite to the browser to provide a robust way of storing and querying data. However, not all browser vendors were convinced, and Mozilla didn’t even attempt to implement it in their Firefox browser.
Another reason it wasn’t well adopted was probably the horrible API for writing queries with callbacks, as shown in example 3.1.
Example 3.1

Support for WebSQL is only available in older versions of the major browsers and some browsers on Android.
4. IndexedDB
IndexedDB has more or less replaced WebSQL but as a NoSQL database.
IndexedDB tables are referred to as object stores, and they support transactions and indexes. Like Web Storage, keys are stored as strings, but the value can be anything from strings to objects, arrays, or even binary data.
Example 4.1

By calling the open method, a specific database (first parameter) will be opened or created if that database doesn’t exist yet. The second parameter of this method is the database’s version. When this version is higher than the current version (including non-existent), it will trigger the onupgradeneeded event, as shown in example 4.2.
Example 4.2
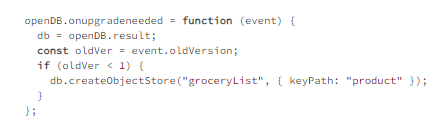
In this event, actions depending on the version can be performed, like creating tables/object stores, indexes or inserting data.
IndexedDB will fire an on success event when everything went right and an on error event in case of errors, including the specific error.
Example 4.3

After successfully opening the database, you can start a transaction to store data, for instance. Transactions are especially useful when multiple actions are performed, and none are allowed to fail. A transaction will ensure that all actions are reverted in case of a failure.
iJS Newsletter
Join the JavaScript community and keep up with the latest news!
idb
While the syntax for using IndexedDB is much better than for WebSQL, there is still room for improvement. Which is why Jake Archibald, formerly from Google, wrote a library called idb. It uses promises instead of events, enabling developers to use async/await. It also provides shortcuts for common transactions like getAll, put, and delete.
Example 4.4 shows a shorter and easier implementation of examples 4.1 through 4.3 with the idb library.
Example 4.4

Data Synchronization
IndexedDB is an excellent solution for ensuring that data is always available for users, even offline or with a lousy internet connection. On startup, data from the server can be synced to IndexedDB for faster response, and when there is an active internet connection, added or changed data can be sent back to the server.
Examples 4.5 through 4.7 show a rudimentary implementation of this using a Web Worker. A Web Worker is similar to a Service Worker, so it runs in a separate thread, not blocking the website but not intercepting any network requests.
Example 4.5
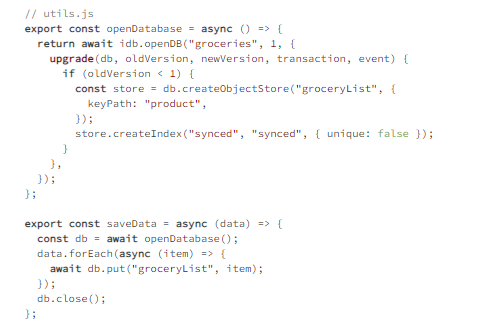
utils.js has shared methods to open or create the database and save data.
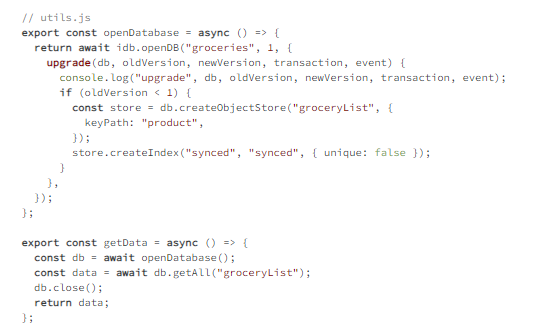
Example 4.6

worker.js imports the idb library and helper methods of utils.js.
It will listen to messages sent to it and call the method *checkNetworkState * when the message equals CheckNetworkState. This method will check every 3 seconds whether the user agent is online. If so, it will attempt to update the server (in this case, a local mock server) by sending a post request (method syncRecords) for every record where synced is false. When successful, the record will be updated and synced will be set to true.
Example 4.7

script.js will instantiate a new worker at the DOMContentLoaded event and post a message to it to start the sync process to the server.
The DOMContentLoaded event fires when the HTML document has been completely parsed and all deferred scripts have been downloaded and executed.
5. File System Access API
The File System Access API enables developers to interact with users’ file system. Two prominent examples of web applications that use this are Adobe Photoshop Online and Visual Studio Code.
Reading and writing files is pretty straightforward using file pickers with options to, for instance, set the file type, folder, suggested file name or allowed extensions.
Example 5.1

Reading a file starts with acquiring a file handle through the file picker, actually getting the file and reading the contents.
Example 5.2

Saving a file also requires a file handle from the file picker to create and write a file.
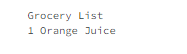
In example 4.4, a grocery list IndexedDB object store was created, and 1 item was added. With the File System Access API, it’s now possible to export this to a text file, as shown in examples 5.3 through 5.5.
Example 5.3

Example 5.4
Example 5.5: contents of file
The File System Access API is still experimental and is currently only supported by Chromium-based browsers on the desktop. Its predecessor is the File API.
File API
The File API uses the Origin Private File System (OPFS), a virtual drive within the browser’s sandbox that does not have access to the actual file system.
Files can only be read and must be provided to the browser using input type=”file” or via drag and drop.
Example 5.4 shows how to add a listener to a file input, read the file, and display it.
Example 5.4
6. AppCache
AppCache, short for Application Cache, was designed to enable web applications to cache resources on the user’s computer. It aimed to make web apps available offline and improve load times by storing assets like HTML files, CSS, JavaScript, and images locally.
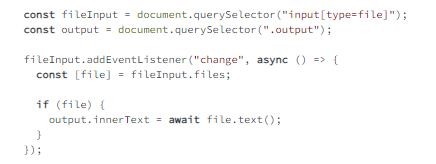
The way to do that was to create a manifest file, usually named offline.appcache, which contained all the information, as shown in example 6.1.
Example 6.1
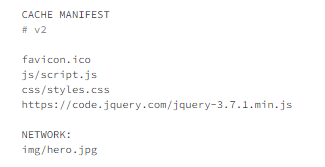
The first line had to be CACHE MANIFEST and, in this case, is followed by a version number of the manifest as a comment.
The following lines show the files that the browser needs to cache. This could even include a remote JavaScript library, for instance.
Files that should never be cached need to be placed after NETWORK:, meaning they should always be retrieved from the server.
Example 6.2
![]()
Application Cache was enabled by adding a manifest attribute to the html tag.
Despite its initial promise, AppCache had several issues:
- Files were only cached if all files in the manifest were available
- The HTML file that has the manifest was cached as well
- Cached files were always served from appcache; there was no way to get the files from the server instead
- HTML updates required an updated manifest; a version number change (as in the comment mentioned before) was enough
For these reasons, and probably more, the Application Cache was depreciated and replaced by Cache Storage in combination with Service Workers. Some Android browsers still support AppCache, but continued use of it is not recommended.
iJS Newsletter
Join the JavaScript community and keep up with the latest news!
7. Cache Storage
Cache Storage, part of the Service Workers API, is designed to store HTTP request/response pairs. It is particularly useful for enabling web applications to work offline and improving load performance.
Other key features that can be achieved with Cache Storage and Service Workers are:
- Network Resilience: In situations with poor network conditions, the Cache Storage can serve as a fallback, delivering cached content when network requests fail.
- Resource Versioning: Cache Storage supports versioning of cached assets. Developers can cache new versions of files and clear out old versions, ensuring users always have access to the latest content.
- Custom Offline Pages: Developers can use Cache Storage to provide custom offline fallback pages. Instead of showing generic browser offline messages, applications can display branded pages, guides on using the app offline, or cached content.
- Pre-caching: Cache Storage allows for pre-caching assets during the service worker installation. This ensures that all essential resources are cached before the user even navigates to a particular part of the site, enhancing the initial load performance.
- API Caching: The Cache API can store responses for frequently requested data for web applications that rely heavily on API calls. This reduces the need for repetitive network requests, saves bandwidth, and improves responsiveness.
Caching data starts with creating, registering, and activating a Service Worker, as shown in examples 7.1 through 7.3.
Example. 7.1: service-worker.js

Example 7.2: index.html
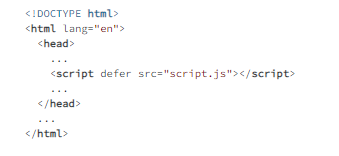
Example 7.3: script.js

Notice that the Service Worker JavaScript file is not loaded from the HTML file but within a JavaScript file. It’s also not necessary to check if navigator.serviceWorker is available in the browser because it’s supported in all modern browsers.
The next step can be to have an explicit list of assets (a static cache) that need to be saved and served from the Cache Storage.
In example 7.4, the name of the static cache and a list of files that need to be saved to it are declared. Next, in example 7.5, the install event is extended to check if a cache already exists. If not, it will be created, and all files will be added.
Example 7.4: service-worker.js
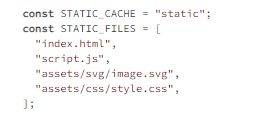
Example 7.5: service-worker.js
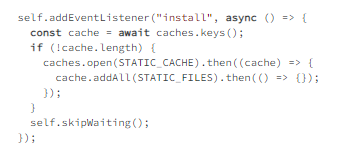
Just adding files to the cache isn’t very useful.
In example 7.6, the function getFromNetworkOrCache checks if the request (the full URL of the requested asset) is available in the Cache Storage. If it is, it retrieves and returns it directly.
If the asset is unavailable in the cache, it will fetch it from the network and serve it to the browser.
Example 7.6 service-worker.js

To enable the functionality from this function, a new EventListener is added to the Service Worker file. Listening to the fetch event allows a Service Worker to catch the request and respond in any way it wants. In this case, it will respond with the result of getFromNetworkOrCache.
Example 7.7: service-worker.js

It’s possible to cache other files as well to go beyond the static list of files. Those dynamic files should be stored in a separate cache. In example 7.8, an extra cache name is declared, and the getFromNetworkOrCache function has been extended.
Example 7.8: service-worker.js
The function now saves a copy of the network response to the dynamic cache. This needs to be a copy of the response; otherwise, the Service Worker hasn’t got anything to return to the browser.
Next time a request with the same URL as a dynamically cached asset comes in, it can be served directly from the Cache Storage.
This particular cache strategy is just one of many possibilities. It can be suited as needed. Other common scenarios in the industry are:
- Cache first; if network data is newer, replace the content
- Network first; if it fails or takes too long, serve from the cache
- Only serve static assets from cache and API calls from the network
8. Final words
Browser Storage is very powerful and versatile, and like everything in programming, the answer to the question “What should I use?” is “It depends.” There is no silver bullet that covers all your needs in every project. All the options have their pros and cons, and you should really think and think again about which one best suits your needs.
A repository with the mentioned storage possibilities is available at Github. It includes a client and server application you can run on your machine to try it out.




